

1. 의사결정나무 모델(Decision Tree Model)
1. 개념
기존에 존재하는 여러가지 알고리즘을 결합 또는 조합하여 새로운 강력한 모델로 만드는 알고리즘
2. 종류 (어떻게 조합되느냐에 따라)
- Voting : 서로 다른 알고리즘을 가진 분류기를 결합하는 방법 / 가장 성능이 좋은 알고리즘을 선택하는 방식

- Bagging : 서로 같은 알고리즘을 선택, 데이터에서 서로 다른 복원추출(Sub Sample)된 데이터를 학습하여 알고리즘을 결합하는 방식 (=매번 랜덤하게 추출 / Random Forest)

- Boosting : 알고리즘을 구성할 때마다, 오차를 줄이는 방향으로 모델의 파라미터를 조정하여 학습해 결합하는 방식

2. 실습
1. Random Forest (Bagging)
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestClassifier #분류모델 라이브러리 설치
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_reportX_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=1234)pipe_list = [('impute', SimpleImputer()),
('model', RandomForestClassifier())]
pipe_model = Pipeline(pipe_list)hyper_parameter = {'model__max_depth' : range(5,10),
'model__criterion':['gini','entropy'],
'model__min_samples_split':range(5,10),
'model__class_weight':['balanced', None],
'model__n_estimators':[50,100,150]} #트리 개수 결정
grid_model = GridSearchCV(pipe_model, param_grid=hyper_parameter, cv=3,
n_jobs = -1, scoring='f1')
grid_model.fit(X_train, Y_train)best_model = grid_model.best_estimator_
Y_train_pred = best_model.predict(X_train)
Y_test_pred = best_model.predict(X_test)
print(classification_report(Y_train, Y_train_pred))
print(classification_report(Y_test, Y_test_pred))
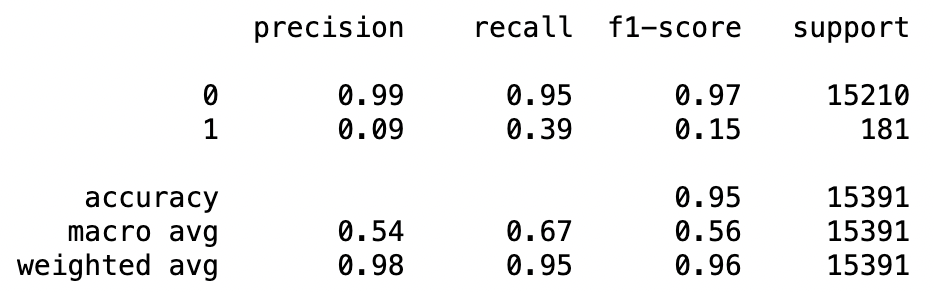
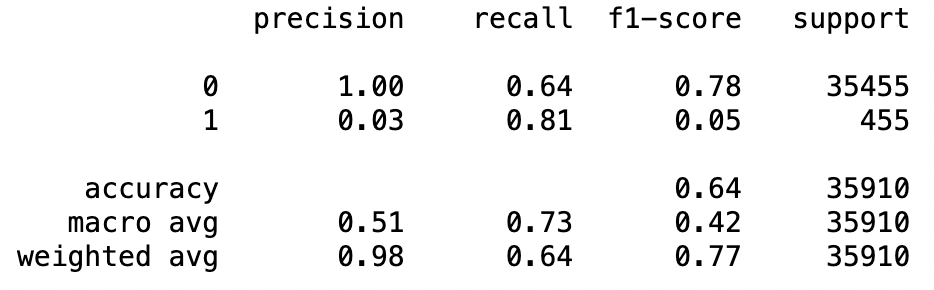

학습 결과를 확인해보면, 이전에 DecisionTree 모델로 학습하였을 때보다 성능이 좋아진 것을 알 수 있다.
2. Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
hyper_parameter = {'model__max_depth':[9],
'model__min_samples_split':[5],
'model__min_samples_leaf':[7],
'model__n_estimators':[200],
'model__n_iter_no_change':[5],
'model__tol':[0.01]}Gradient Boosting을 위한 라이브러리를 설치하고, 해당 방법에 맞게 파라미터를 조정한다.
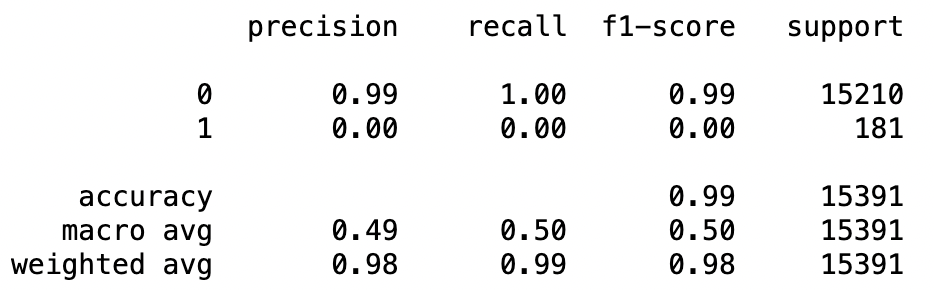
이외 코드는 위와 동일하게 한 후, 학습/검증 데이터와 예측값을 비교해보면 아래와 같은 결과를 확인할 수 있다.
print(classification_report(Y_train, Y_train_pred))
print(classification_report(Y_test, Y_test_pred))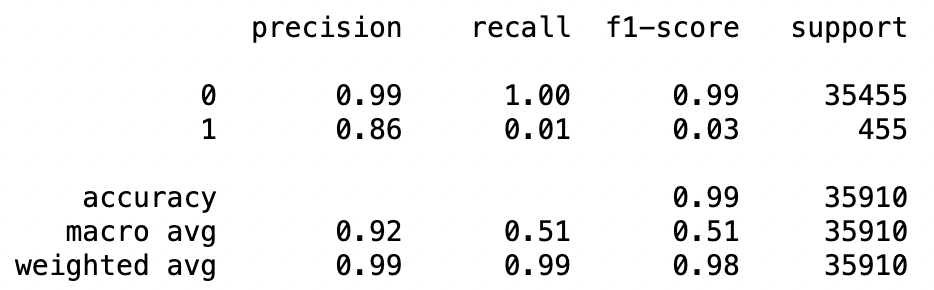
'Machine Learning' 카테고리의 다른 글
| 분류모델 | ① 의사결정나무 모델(Decision Tree Model) (0) | 2024.03.01 |
|---|---|
| 특성공학 | ⑤ 샘플링(Sampling) (0) | 2024.02.29 |
| 특성공학 | ④ 하이퍼 파라미터 튜닝(Hyper Parameter Tuning) (0) | 2024.02.29 |
| 특성공학 | ③ 교차 검증(Cross Validation) (0) | 2024.02.29 |
| 특성공학 | ② 차원축소(Scaling) & 데이터 변환(Encoding) (0) | 2024.01.26 |